SAN FRANCISCO--(BUSINESS WIRE)--Jun 22, 2023--
MosaicML announces the availability of MPT-30B Base, Instruct, and Chat, the most advanced models in their MPT (MosaicML Pretrained Transformer) series of open-source large language models. These state-of-the-art models - which were trained with an 8k token context window - surpass the quality of the original GPT-3 and can be used directly for inference and/or as starting points for building proprietary models. They were trained on the MosaicML Platform using - in part - NVIDIA’s latest-generation H100 accelerators, which are now available for MosaicML’s customers. By building on top of MPT-30B, businesses can harness the power of generative AI without compromising security or data privacy.
This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20230622195151/en/
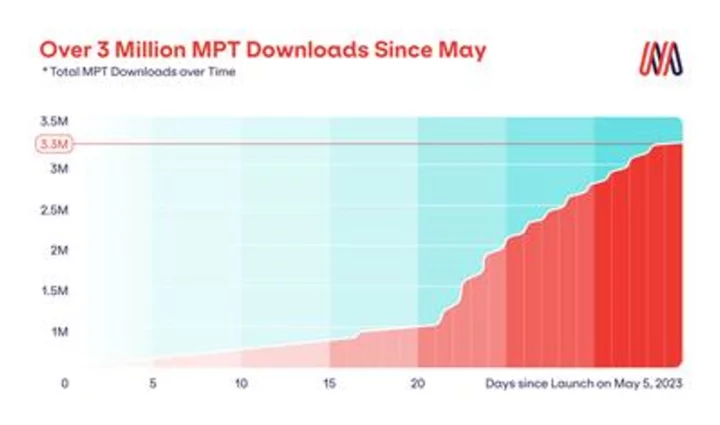
Over 3 Million MPT Downloads Since May (Graphic: Business Wire)
Over 3 Million MPT Downloads since May
The MosaicML MPT family of models are already some of the most powerful and popular open-source language models available for commercial use today. Since launching on May 5, 2023, the MPT-7B models (Base, Instruct, Chat, StoryWriter) have been downloaded over 3.3 million times. Today’s release extends the MPT family with larger, higher quality MPT-30B models that unlock even more applications. As always, MosaicML’s MPT models are optimized for efficient training and inference.
MPT-30B surpasses GPT-3
As we pass the 3rd anniversary of GPT-3, it’s noteworthy to point out that MPT-30B was designed to surpass the quality of this iconic model. When measured using standard academic benchmarks, MPT-30B outperforms the originally published GPT-3.
Furthermore, MPT-30B achieves this quality target while using ~1/6th the number of parameters – GPT-3 has 175 billion parameters while MPT-30B has only 30 billion parameters. This means MPT-30B is easier to run on local hardware and much cheaper to deploy for inference. Starting today, developers and enterprises can build and deploy their own commercially viable enterprise grade GPT-3 quality models. It was also trained at a cost that was orders of magnitude lower than estimates for the original GPT-3, putting the ability to train custom GPT-3 models within the reach of enterprises.
Finally, MPT-30B was trained on longer sequences (up to 8,000 tokens) than GPT-3, the popular LLaMA family of models, and the recent Falcon model (2,000 each). It is designed to handle even longer sequences in practice, making it a perfect fit for data-heavy enterprise applications.
Training on H100 GPUs now available for MosaicML customers
MPT-30B is the first publicly known LLM trained on NVIDIA H100 GPUs, thanks to the leading flexibility and reliability of the MosaicML platform. Within days of hardware delivery, the MosaicML team was able to seamlessly move the MPT-30B training run from its original A100 cluster to a new H100 cluster – increasing throughput-per-GPU by over 2.4x and resulting in a faster finish time. MosaicML is committed to bring the latest advances in hardware and software within reach of all enterprises – enabling them to train models faster and for lower cost than before.
Times and costs to pretrain MPT-30B from scratch on 1 trillion tokens.
Hardware | Precision | Model | Tokens | Time to Train with MosaicML | Cost to Train with MosaicML |
512xA100-40GB | AMP_BF16 | MPT-30B | 1 Trillion | 28.3 Days | ~ $871,000 |
512xH100-80GB | AMP_BF16 | MPT-30B | 1 Trillion | 11.6 Days | ~ $714,000 |
Times for H100 are extrapolated from a 256xH100 system. Costs are based on current MosaicML reserved cluster pricing of $2.50/A100-40GB/hour and $5.00/H100-80GB/hour as of June 22nd, 2023. Costs are subject to change. |
Finetuning times and costs for MPT-30B on smaller systems.
Hardware | Precision | Model | Time to Finetune on 1B tokens with MosaicML | Cost to Finetune on 1B tokens with MosaicML |
16xA100-40GB | AMP_BF16 | MPT-30B | 21.8 Hours | $871 |
16xH100-80GB | AMP_BF16 | MPT-30B | 8.9 Hours | $714 |
Costs are based on current MosaicML reserved cluster pricing of $2.50/A100-40GB/hour and $5.00/H100-80GB/hour as of June 22nd, 2023. Costs are subject to change. |
MosaicML MPT: Powering a New Generation of AI Applications
Enterprises are deploying MPT models for use cases like code completion and dialogue generation, as well as fine-tuning these models with their own proprietary data.
Replit, the world’s leading web-based IDE, was able to build a new code generation model using their proprietary data together with MosaicML’s training platform in just three days. Their custom MPT model, replit-code-v1-3b, significantly improved the performance of their GhostWriter product in terms of speed, cost, and code quality.
Scatter Lab, a cutting-edge AI startup building ‘social AI chatbots’ that enable engaging, human-like conversations, trained their own MPT model from scratch to power a custom chatbot. This model, one of the first multilingual generative AI models that can understand both English and Korean, enables new chat experiences for their 1.5 million users.
Worldwide travel and expense management software company Navan is building their custom LLMs on the MPT foundation.
“ At Navan, we use generative AI across our products and services, powering experiences such as our virtual travel agent and our conversational business intelligence agent. MosaicML’s foundation models offer state-of-the-art language capabilities, while being extremely efficient to fine-tune and serve inference at scale. We are excited to see how this promising technology develops,” said Ilan Twig, co-founder and chief technology officer at Navan.
MPT-30B is designed to accelerate model development for enterprises who want to build their own language models for chat, question answering, summarization, extraction, and other language applications.
How Developers can use MPT-30B today
MPT-30B is fully open source and is available for download through the HuggingFace Hub. Developers can fine-tune MPT-30B on their data, as well as deploy the model for inference on their own infrastructure. For a faster and easier experience, developers can run model inference using MosaicML's MPT-30B-Instruct managed endpoint, which relieves developers from the need to secure GPU capacity and takes care of the serving infrastructure. At a price of $0.005/1K tokens, MPT-30B-Instruct is 4-6X cheaper than comparable endpoints like OpenAI DaVinci. Refer to the MPT-30B blog for full technical details.
About MosaicML
MosaicML's mission is to enable organizations to easily, efficiently, and affordably build and deploy state-of-the-art AI. We were founded with the belief that a company’s data is its most valuable core IP, and models are the most powerful expression of that data. Running on any cloud, the MosaicML generative AI platform allows anyone to securely train and deploy models with their own data in their own tenancy. With a focus on security, privacy, and performance, MosaicML delivers powerful AI models that enable organizations to unlock the full potential of AI technology.
View source version on businesswire.com:https://www.businesswire.com/news/home/20230622195151/en/
press@mosaicml.com
KEYWORD: UNITED STATES NORTH AMERICA CALIFORNIA
INDUSTRY KEYWORD: DATA MANAGEMENT ONLINE PRIVACY SECURITY TECHNOLOGY OTHER TECHNOLOGY SOFTWARE ARTIFICIAL INTELLIGENCE
SOURCE: MosaicML
Copyright Business Wire 2023.
PUB: 06/22/2023 10:00 AM/DISC: 06/22/2023 09:59 AM
http://www.businesswire.com/news/home/20230622195151/en







